Revolutionising Information Retrieval with Generative AI (Text-to-SQL)


Introduction
The constant evolution of artificial intelligence has given rise to innovative solutions, and our latest project is at the forefront of this revolution. Combining the capabilities of Generative AI with Text Generation, we’ve developed an Information Retrieval system in Python that aims to redefine the way users interact with databases. This blog post provides an in-depth exploration of the project’s architecture, key functionalities, and the significance it holds in the realm of AI-driven information retrieval.
Important Features
Bridging the Gap: Text Generation and Information Retrieval
The convergence of text generation and information retrieval is a pivotal development that empowers systems to understand and respond to natural language queries effectively. Our project harnesses advanced techniques from Natural Language Processing (NLP) and Generative AI to create an intelligent system that seamlessly interprets user prompts and retrieves relevant information.
Streamlining Queries with Pattern Matching and Lemmatisation
The heart of our project lies in the nlp_search function, a powerful tool that takes user prompts and refines them using sophisticated techniques. By employing pattern matching and lemmatization, the function ensures that user inputs are processed into structured SQL queries with precision and accuracy. The integration of the Pattern Matcher and spaCy library enhances the system’s ability to understand and respond to diverse queries.
Database Connectivity and Schema Design
Flexibility is key in any robust information retrieval system. To cater to diverse database structures, we’ve provided users with the ability to define their schema in an SQL file. The get_data_from_db function establishes a connection to the specified database, executes the generated SQL query, and organizes the retrieved data into a 2D array. This modular approach allows users to seamlessly integrate our project with their existing data structures.
Flow Diagram:
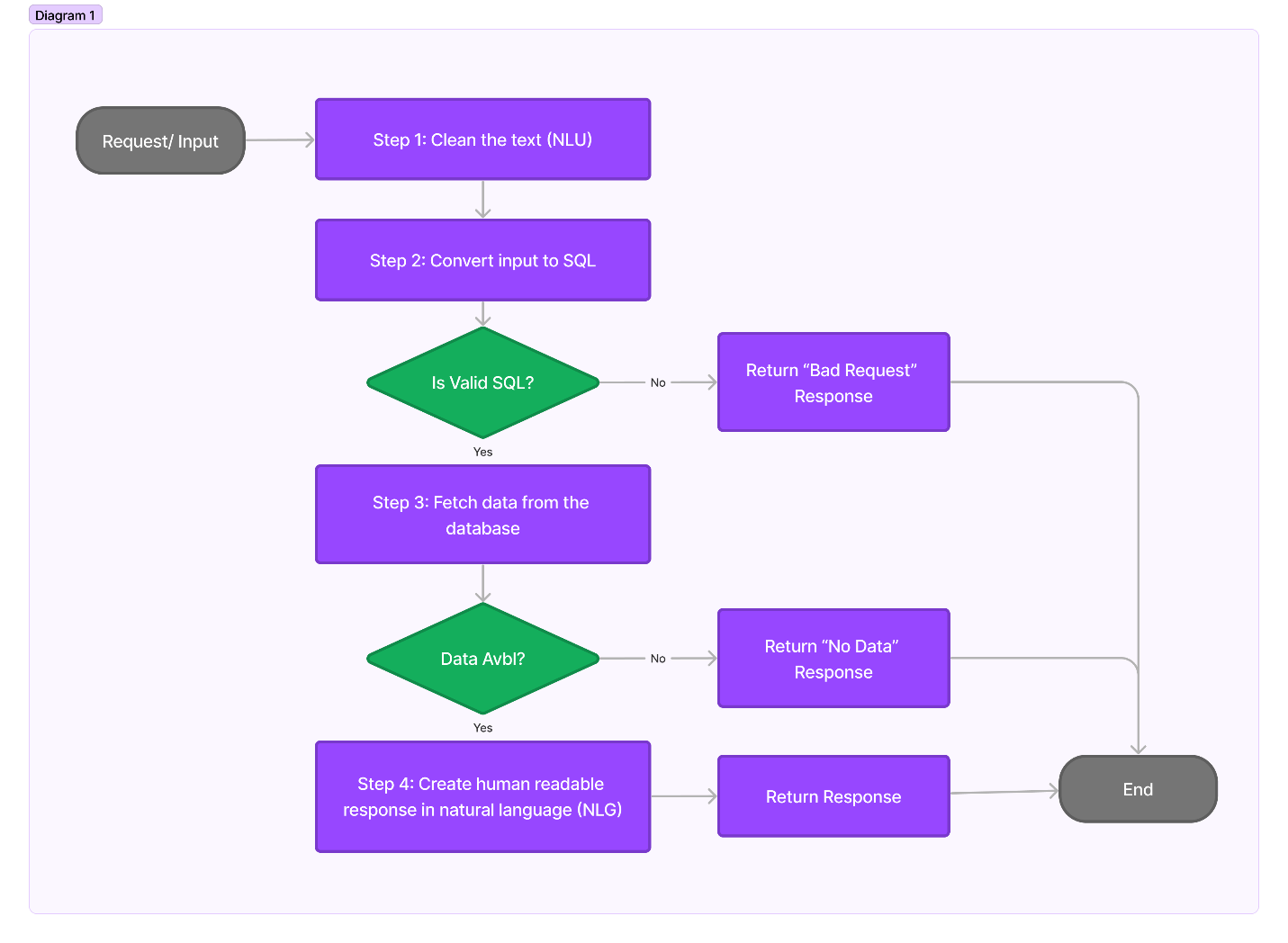
Project in Action: Code Walkthrough
The nlp_search function in “main.py” is the starting point. It executes other sub-functions to generate the final response.
def nlp_search(prompt):
try:
#step 1:
final_prompt = clean_prompt(prompt, nlp, matcher)
#step 2:
sql_query = prepare_sql_statement(final_prompt, ln2sql_obj)
#step 3:
data = get_data_from_db(sql_query)
#step 4:
response = nlp_generate_response(prompt, data, nlp)
return response
except:
print("nlp_search failed. error.")
return "Failed to get result."The “main.py” also loads global AI models at startup
if __name__ == "__main__":
nltk.download("punkt")
nltk.download('wordnet')
nlp = spacy.load('en_core_web_sm')
matcher = Matcher(nlp.vocab)
add_spacy_matcher(matcher)
ln2sql_obj = Ln2sql(
database_path=os.path.dirname(__file__) + "/database_store/insurance.sql",
language_path=os.path.dirname(__file__) + "/lang_store/english.csv",
json_output_path="",
thesaurus_path="",
stopwords_path="",
)Step 1: Cleaning the Prompt (NLU)
The clean_prompt function serves as the first step in preparing user queries for efficient retrieval. This multifaceted function replaces words from a predefined dictionary, handles date-related queries by converting them into actual dates, and incorporates additional language operations. The result is a cleaned and refined prompt that sets the stage for accurate information retrieval.
def clean_prompt(prompt, nlp, matcher):
final_prompt = re.sub(r'\s+', ' ', prompt)
final_prompt = lookup_dates(final_prompt, nlp)
final_prompt = lookup_words_nlp(final_prompt, nlp, matcher)
doc = nlp(final_prompt)
final_prompt = lemmatize_text(final_prompt, nlp)
return final_promptIt uses a matcher to train the model to fine-tune the “prompt”. In the below code, this function will add the ability to the matcher to replace “policy #”, “policy number” or “policy no” (with or without space or special char) with the “policy_number” word which is the database entity field.
def add_spacy_matcher(matcher):
patterns = []
patterns.append([{'LOWER': 'policynumber'}])
patterns.append([{'LOWER': 'policy'}, {'LOWER': 'number'}])
patterns.append([{'LOWER': 'policy'}, {'IS_PUNCT': True, 'OP':'*'}, {'LOWER': 'number'}])
patterns.append([{'LOWER': 'policyno'}])
patterns.append([{'LOWER': 'policy'}, {'LOWER': 'no'}])
patterns.append([{'LOWER': 'policy'}, {'IS_PUNCT': True, 'OP':'*'}, {'LOWER': 'no'}])
patterns.append([{'LOWER': 'policy#'}])
patterns.append([{'LOWER': 'policy'}, {'LOWER': '#'}])
matcher.add('policy_number', patterns)Step 2: SQL Query Generation (Text-to-SQL)
The prepare_sql_statement function utilizes the Ln2Sql library to convert the cleaned prompt into a structured SQL query. This step is critical in ensuring that user intent is accurately translated into a format understandable by the database. The generated SQL query lays the groundwork for effective data retrieval.
def prepare_sql_statement(prompt, ln2sql_obj):
sql_query = ln2sql_obj.get_query(prompt)
sql_query = " ".join(sql_query.split())
return sql_queryStep 3: Database Interaction
The get_data_from_db function establishes a connection to the specified database and executes the generated SQL query. The retrieved data is organized into a 2D array, where the 0th array contains column headers, and subsequent arrays represent data values. This organized structure is pivotal for creating a human-readable response.
def get_data_from_db(sql_query):
data = []
con = sqlite3.connect("./database_store/sample.db")
#connect to the database and fetch result in 2d List
cur = con.cursor()
cur.execute(sql_query)
# Fetch the column names from the cursor's description
column_names = [member[0] for member in cur.description]
data.append(column_names)
myresult = cur.fetchall()
for x in myresult:
data.append(list(x))
return dataStep 4: Generating Human-like Text Response (NLG)
The nlp_generate_response function transforms the fetched data into a coherent and human-like text response. Whether the user is querying a single data point or multiple values, this function ensures that the response is informative, structured, and easily comprehensible. We have used a Hugging face transformer to generate human-like text by providing original prompts and answer hints as input to the model.
import re #import hugging face transformers from transformers import T5Tokenizer, T5ForConditionalGeneration# step 4: This function sould generate human readable response def nlp_generate_response(prompt: str, data, nlp): prompt = re.sub(r'\s+', ' ', prompt) data_string = "" if len(data) > 1: data_count = len(data[0]) if data_count == 1: data_string = str(data[1][0]) elif data_count > 1: index = 0 for labal in data[0]: data_string += f"{labal.replace('_', ' ').title()} is {data[1][index]}" if index == data_count - 2: data_string += " and " elif index != data_count - 1: data_string += ", " index += 1 #initialize model from Hugging face tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base") model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base") input_text = f"Create statement from question and answer. {prompt} \n Answer: {data_string}" input_ids = tokenizer(input_text, return_tensors="pt", max_new_tokens=50).input_ids outputs = model.generate(input_ids) return tokenizer.decode(outputs[0])
Conclusion
In conclusion, our Information Retrieval project represents a significant leap forward in leveraging Generative AI and text generation for database interactions. By incorporating advanced NLP techniques, database connectivity, and SQL query generation, we aim to revolutionize the way users interact with and extract information from databases. This project not only showcases the capabilities of modern AI but also sets the stage for future advancements in intelligent information retrieval systems. The fusion of Generative AI and information retrieval is a potent force, and our project stands as a testament to the endless possibilities that emerge at this intersection.